

GTO Wizard 最近进行了一项展示性实验,测试现代 AI 在扑克中的实际水平。其自研智能体与多款主流大语言模型进行了单挑对局,参赛者从 GPT-5.4 到 Kimi K2.5 不等,结果非常明确:所有模型都被全面压制。
5,000手对局,LLM毫无胜算
随着 AI 持续渗透到搜索、编程和高级分析等日常场景,人们自然也开始关注,它在信息不完全博弈中的表现究竟如何——而扑克正是最典型的测试场景之一,因为它同时要求策略、数学计算和动态适应能力。
2025 年底公布的首批结果显示,通用模型已经具备一定竞争力,但距离稳定打出高水平表现仍有明显差距。而在这次最新实验中,LLM 不再彼此对战,而是直接面对专业扑克 AI。
GTO Wizard 公布了一项大规模基准测试结果:其专用 AI 与主要语言模型逐一交手。结论没有悬念,GTO Wizard AI 以明显优势击败全部对手。
GTO Wizard 是一个基于 GTO 理论开发扑克训练平台与云端求解器的团队。
GTO Wizard 的基准测试如何进行
本次实验覆盖了主要模型,包括多个版本的 GPT、Claude、Gemini、Grok 和 Kimi。
所有参赛者都在完全相同的条件下进行测试:
- No-Limit Texas Hold’em
- 200bb 深筹码
- 单挑共进行 5,000 手
- 采用统一评估方法 AIVAT——该系统可将运气波动影响大约降低 10 倍,并从 GTO 角度衡量决策质量,而不是只看牌桌上的原始输赢结果
有一个细节值得注意:开发团队没有明确说明结果中是否计入抽水。不过,即便按 5% 抽水重新估算,整场对抗的总体结论也不会改变。
结果:彻底碾压
最终结果非常清晰:所有模型的成绩都显著为负。
- GPT-5.3 XHigh Reasoning 的成绩最好,为 -16 bb/100。作为对比,顶级单挑职业玩家在与其他玩家对抗时,通常能维持大约 +4 bb/100 的水平,这也是 GTO Wizard 使用的精英基准。
- GPT-5.4 Nano (No Reasoning) 成绩最差,为 -189.7 bb/100。
| 排名 | 模型 | 开发方 | 经运气校正后的胜率(bb/100) | 标准差 |
| 1 | GPT-5.3 (XHigh Reasoning) | OpenAI | -16.0 | ±3.0 |
| 2 | Marvel | MIT | -14.0 | ±4.7 |
| 3 | GPT-5.4 (XHigh Reasoning) | OpenAI | -17.8 | ±3.7 |
| 4 | GPT-5.3 (High Reasoning) | OpenAI | -18.2 | ±3.9 |
| 5 | Claude Opus 4.6 | Anthropic | -20.4 | ±4.4 |
| 6 | Gemini 3.1 Pro | ~-30.8 | — | |
| 7 | Kimi K2.5 | Moonshot AI | ~-40 to -50 | — |
| 8 | Grok 4 | xAI | ~-60 | — |
| 9 | GPT-4o / older baselines | OpenAI | < -100 | — |
| 10 | GPT-5.4 Nano (No Reasoning) | OpenAI | -189.7 | — |
为什么 LLM 会输
在复盘大量手牌后,GTO Wizard 团队总结出四个系统性原因,解释了为什么通用模型无法在扑克中达到高水平:
- 隐藏信息:模型看不到对手底牌,只能完全依赖概率进行判断。
- 范围平衡:扑克中存在成千上万种局面,哪怕极小的策略失衡也会被针对性利用。
- 长期规划:每条街的决策都会影响后续行动,错误会逐步累积成 EV 损失。
- 在不确定性下对对手行为建模:这需要非常强的概率模型,而 LLM 并不显式具备这种能力。
团队还指出了一个根本性问题:即便是先进模型,在大约 2% 的情况下仍会误读自己的手牌,混淆花色和牌型。在扑克中,这类错误会立刻转化为负 EV。
GTO Wizard AI 的实力来自哪里
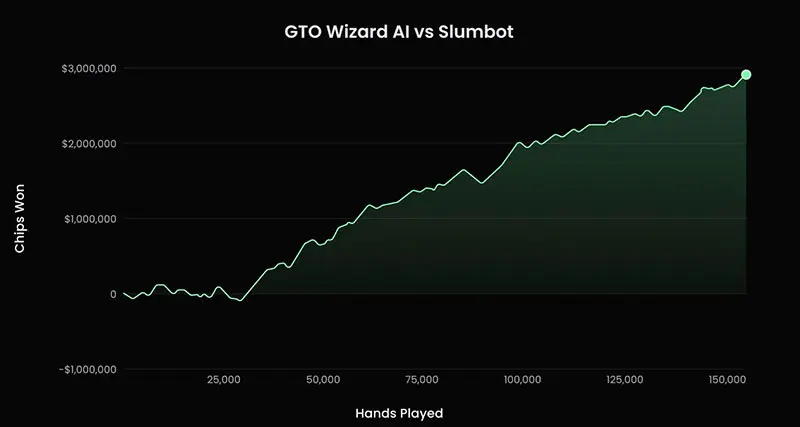
开发团队强调,GTO Wizard AI 的打法接近 Nash equilibrium,因此极难被对手利用。
他们使用的大致基准是:顶级玩家对普通对手群体的优势约为 4 bb/100。但按照该模型的逻辑,即便达到这一水准的人类高手,面对专业 AI 依然会处于下风。
这套系统的技术基础来自 Ruse AI,由加拿大研究人员 Philippe Birdsell 和 Marc-Antoine Provost 开发。2023 年,它曾在 150,000 手样本中以 +19.4 bb/100 的成绩击败公开领域最强扑克机器人之一 Slumbot。该项目随后被整合进 GTO Wizard 生态,并成为当前 AI 引擎的核心基础。
此外,这项实验的形式本身也值得关注。GTO Wizard 已将该基准测试公开,任何开发者都可以通过 API 接入自己的智能体,并参加同样的单挑测试。这实际上让该系统成为评估扑克 AI 的统一标准,也让不同模型能够在相同条件下进行直接对比。
GTO Wizard 对阵 LLM:核心结论
这项实验的结论非常明确:通用型语言模型目前仍无法与专业扑克智能体竞争,即便是在单挑这种相对简化的场景中也是如此。
这场对抗所暴露出的差距并非偶然,而是方法路径上的系统性差异。它清楚地展示了当前能力边界:一边是通用智能,另一边是高度专业化的优化系统。
在这个意义上,扑克不只是游戏,也是一项能够严格检验现代 LLM 能力与极限的基准测试。
更多扑克策略、行业资讯,请持续关注 PokerProGo。



{kind=link}