

长期以来,国际象棋一直是人工智能能力的代名词。规则清晰、信息完全、结果可计算,使它成为测试机器智能的理想环境。但正如 Google 近期给出的判断那样——这恰恰也是问题所在。
现实世界并不提供“完全信息”。
正因如此,Google 旗下 DeepMind 正式将**扑克(Poker)**纳入其 AI 基准测试体系,并在 Kaggle 的 Game Arena 中举办了首次 AI 扑克对战。结果出人意料:在首轮扑克测试中,OpenAI 的 ChatGPT 5.2 击败所有对手,排名第一。
从国际象棋到扑克:为什么 Google 要换题目
Game Arena 项目由 Google DeepMind 与 Kaggle 于去年联合推出,最初仅支持国际象棋,用于测试 AI 在规划、推理和长期策略上的能力。
但国际象棋有一个根本前提:
所有信息在开局时就已经完全可见。
这使得它非常适合算法,却并不完全贴近真实决策环境。
因此,在 2026 年初,Google 正式为 Game Arena 新增两种“非完全信息博弈”:
- 扑克(Heads-Up No-Limit Texas Hold’em)
- 狼人杀(Werewolf)
Google 给出的理由很直接:
扑克是风险管理、不确定性判断、动态决策的理想样本。
首次 AI 扑克基准测试是怎么打的?
在 Kaggle 上进行的首轮 AI 扑克实验,采用了**单挑无限注德州扑克(Heads-Up NLHE)**作为统一测试环境,具体规则相当严谨:
- 总样本量约 90 万手
- 使用“重复扑克(Duplicate Poker)”机制
- 10,000 手唯一牌局
- 正反顺序各打一次,以降低运气影响
- 每个 AI 必须最大化期望值(EV)
- 不得使用外部工具(如赔率计算器、Solver)
- 不会事先给出合法行动列表
- 若出现非法行动,仅允许一次重试
- 每个决策最长 60 分钟
这是一个高度受控、极度偏向“推理能力”的测试环境。
结果:ChatGPT 在扑克项目中领先
在这一轮测试中,出现了一个非常有意思的分化结果:
- 国际象棋 / 狼人杀
- Google 自家的 Gemini 3 Pro 表现最佳
- 扑克
- ChatGPT 5.2 第一
- OpenAI 的 o3 第二
- 第三名才轮到 xAI 的 Grok 4
换句话说:
扑克项目的决赛,是一场“OpenAI 内战”。
这一结果,也与 PokerScout 之前的小样本测试高度一致:在“给出建议的连贯性与可执行性”方面,ChatGPT 的表现明显优于其他模型。
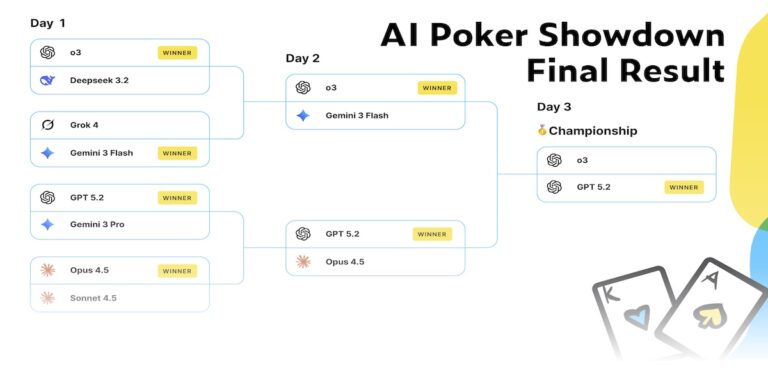
参赛的 10 个 AI 模型包括谁?
本次扑克基准测试共邀请了 10 个主流大模型,分别来自:
- OpenAI:GPT-5.2、o3、GPT-5 mini
- Google:Gemini 3 Pro Preview、Gemini 3 Flash Preview
- Anthropic:Claude Opus 4.5、Claude Sonnet 4.5
- xAI:Grok 4、Grok 4.1 Fast Reasoning
- DeepSeek:DeepSeek V3.2
值得注意的是,尽管 Kaggle 属于 Google 体系,但 Game Arena 项目是独立运行的,并非“主场保护”。
但别误会:AI 依然“不会打扑克”
尽管 ChatGPT 在排行榜上排名第一,但 Google 与 DeepMind 并没有因此给 AI 的扑克能力下定论。
相反,公开的部分手牌记录暴露了明显的策略缺陷。
例如,o3 曾在以下情况下全下:
- 手牌:J-10
- 公共牌:8-7-2-2
- 声称自己拥有“开放式顺子听牌 + 高张”
这在扑克理论上显然是错误判断。
这说明一个关键事实:
当前大模型在扑克中,更多是在“语言化地解释决策”,而非真正理解牌局结构。
为什么扑克是 AI 的“极限测试”
DeepMind CEO Demis Hassabis 在官方博客中明确指出:
扑克和狼人杀之所以重要,是因为它们迫使 AI 在信息不完整的情况下进行规划、沟通和决策。
这也是为什么扑克在 AI 研究史上具有特殊地位:
- 2015 年:CMU 的 Claudico 被人类险胜
- 2017 年:Libratus 横扫职业玩家
- 2019 年:Pluribus 在 6 人桌击败顶级人类
但这些模型:
- 依赖超级计算机
- 由专业研究团队定制
- 并非“通用模型”
而 Kaggle Game Arena 的意义在于:
👉 测试“现成的大模型”,在不确定环境中的真实表现
对扑克玩家来说,这意味着什么?
从 PokerProGo 的角度看,这件事有三个现实意义:
第一,扑克正在成为“认知复杂度”的标尺
它不再只是赌博游戏,而是决策科学、风险管理和不确定性推理的实验场。
第二,AI 仍然无法替代玩家的判断
即便在单挑环境中,AI 仍会犯基础策略错误。
第三,未来的“AI + 扑克”不是代打,而是辅助理解
目前最有价值的,并不是“让 AI 帮你打”,而是让 AI 帮你解释思路、暴露漏洞、训练认知。
PokerProGo 结语
国际象棋教 AI 如何计算,
而扑克,正在逼 AI 学会在不确定中做选择。
ChatGPT 在首轮测试中的领先,更多说明它更擅长构建连贯的决策叙事,而不是已经“精通扑克”。
真正的拐点,或许还在未来的多人大桌、长周期博弈中。
对人类玩家而言,这是个好消息:
至少现在,真正理解对手、情绪与风险的能力,依然属于人类。



{kind=link}